2부에서 뉴스 카테고리에 따라 형태가 다를 수 있음을 확인했습니다. (일반, 연예, 스포츠)
https://datawithyong.tistory.com/7
네이버 뉴스 본문 크롤링 - 2부: 본문 내용 크롤링
1부에 이어 이번에는 네이버뉴스 기사 본문 내용을 수집하겠습니다. https://datawithyong.tistory.com/6 네이버 뉴스 본문 크롤링 - 1부: 본문 링크 출력 데이터 분석 10년차로 얻은 많으 경험을 공유하고
datawithyong.tistory.com
실제로 그대로 적용했을 때 오류가 발생됩니다. (NoneType error)

url = 'https://search.naver.com/search.naver?where=news&sm=tab_jum&query=%EB%89%B4%EC%A7%84%EC%8A%A4'
response = requests.get(url)
html = response.text
soup = BeautifulSoup(html, 'html.parser')
articles = soup.select('div.info_group') # 뉴스 기사 10개 추출
for article in articles:
links = article.select('a.info')
if len(links) == 2:
url = links[1].attrs['href']
response_article = requests.get(url, headers={'User-agent': 'Mozila/5.0'})
html = response_article.text
soup = BeautifulSoup(html, 'html.parser')
content = soup.select_one('#newsct_article')
print(content.text)
---------------------
조건문을 추가해서 다른 형태를 포괄시켜보겠습니다.


import time
for article in articles:
links = article.select('a.info')
if len(links) == 2:
url = links[1].attrs['href']
response_article = requests.get(url, headers={'User-agent': 'Mozila/5.0'})
html = response_article.text
soup = BeautifulSoup(html, 'html.parser')
# 만약 연예 뉴스 경우
if 'entertain' in url:
content = soup.select_one('#articeBody')
else:
content = soup.select_one('#newsct_article')
print(content.text)
time.sleep(0.3)
여전히 오류??!!
리다이렉션 이슈
즉, 'entertain' 이 포함된 주소는 원시 URL이 보내진 주소이고,
우리가 원시 URL에서 포함여부를 확인했기 때문에 else 조건문으로 빠진 것
조금 더 구체적으로 url을 찍어보겠습니다:
import time
for article in articles:
links = article.select('a.info')
if len(links) == 2:
url = links[1].attrs['href']
print(url)
# response_article = requests.get(url, headers={'User-agent': 'Mozila/5.0'})
# html = response_article.text
# soup = BeautifulSoup(html, 'html.parser')
# # 만약 연예 뉴스 경우
# if 'entertain' in url:
# content = soup.select_one('#articeBody')
# else:
# content = soup.select_one('#newsct_article')
# print(content.text)
# time.sleep(0.3)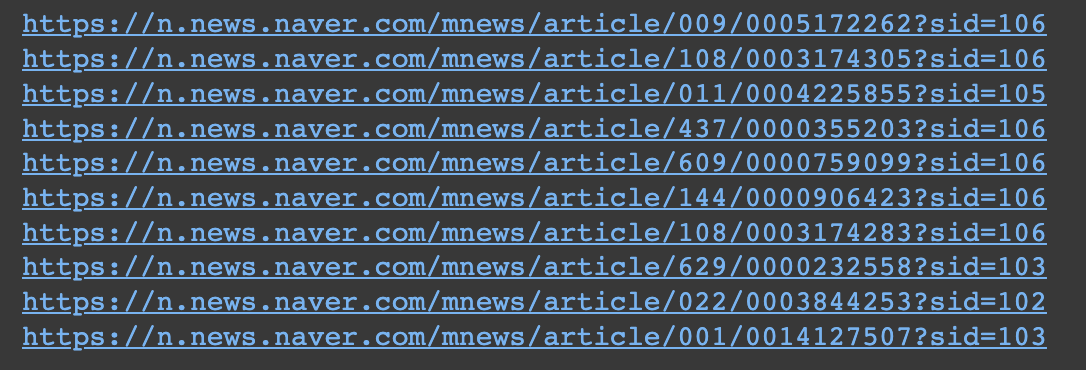
entertain 문자열이 없음을 확인할 수 있습니다.
해당 주소 임의의 1개를 클릭하여 재진입한 주소를 보면 entertain이 있음을 확인할 수 있습니다!
즉, url 대신 response_article.url로 재진입한 주소를 찍어보겠습니다.
import time
for article in articles:
links = article.select('a.info')
if len(links) == 2:
url = links[1].attrs['href']
response_article = requests.get(url, headers={'User-agent': 'Mozila/5.0'})
html = response_article.text
soup = BeautifulSoup(html, 'html.parser')
print(response_article.url)
# # 만약 연예 뉴스 경우
# if 'entertain' in response.url:
# content = soup.select_one('#articeBody')
# else:
# content = soup.select_one('#newsct_article')
# print(content.text)
# time.sleep(0.3)
조건문을 실행하여 본문을 크롤링 하겠습니다.
import time
for article in articles:
links = article.select('a.info')
if len(links) == 2:
url = links[1].attrs['href']
response_article = requests.get(url, headers={'User-agent': 'Mozila/5.0'})
html = response_article.text
soup = BeautifulSoup(html, 'html.parser')
# print(response_article.url)
# 만약 연예 뉴스 경우
if 'entertain' in response_article.url:
print('yes')
print(response_article.url)
content = soup.select_one('#articeBody')
else:
content = soup.select_one('#newsct_article')
print(content.text)
time.sleep(0.3)
링크, 제목, 본문을 깔끔한 형태로 수집해 보겠습니다.
import time
for article in articles:
links = article.select('a.info')
if len(links) == 2:
url = links[1].attrs['href']
response_article = requests.get(url, headers={'User-agent': 'Mozila/5.0'})
html = response_article.text
soup = BeautifulSoup(html, 'html.parser')
# print(response_article.url)
# 만약 연예 뉴스 경우
if 'entertain' in response_article.url:
title = soup.select_one('h2.end_tit')
content = soup.select_one('#articeBody')
else:
title = soup.select_one('#title_area')
content = soup.select_one('#newsct_article')
print('*********링크**********\n', url)
print('=========제목==========\n', title.text.strip())
print('---------본문----------\n', content.text.strip())
time.sleep(0.3)---------------------
스포츠 뉴스 크롤링은 여러분이 시도해 보시고 안 될 경우 댓글에 남겨주세요!
'데이터분석' 카테고리의 다른 글
| 네이버 뉴스 본문 크롤링 - 2부: 본문 내용 크롤링 (0) | 2023.08.13 |
|---|---|
| 네이버 뉴스 본문 크롤링 - 1부: 본문 링크 출력 (0) | 2023.08.13 |
| KB 국민은행 제5회 Future Finance A.I. Challenge (0) | 2023.08.12 |


